
作者:曹乃勋,新炬网络高级技术专家。
年前接到一个ERP迁移的项目,这个项目我是半路杀入,我之所以想为这个项目写点什么,是因为三个原因:一是因为这个项目涉及目前比较热的去IOE和私有云;二则是我觉得如果仅仅站在技术的角度来看,这个项目中的系统所涉及的架构,应该是有问题的。也许以后有人遇到类似的项目,可能会有所借鉴,少走弯路;三则也希望能抛砖引玉,相互交流。
这个项目的主要任务是将不同平台不同架构的系统迁移到一个统一的x86平台中的资源池中,达到从烟囱式管理到统一平台管理的目的。所谓的资源池,其实就是一个6个节点的cluster,但这个6个节点,却被人为的分成三组。这种框架是我们一家兄弟公司设计的,我后来跟他们的工程师沟通当时这么设计的目的,据他们说他们当时设计这样一个架构的目的是为向客户推销他们的一体机,结果一体机没有推销成功,就用在这个x86平台上了。我不清楚这个架构是否适合他们的一体机,但应该是不适合x86平台。但因我们是后期介入,想更改架构代价太大,也只能延续原有的架构来推进项目了。
新的x86平台的架构如下(这里仅仅截取数据库环境部分):
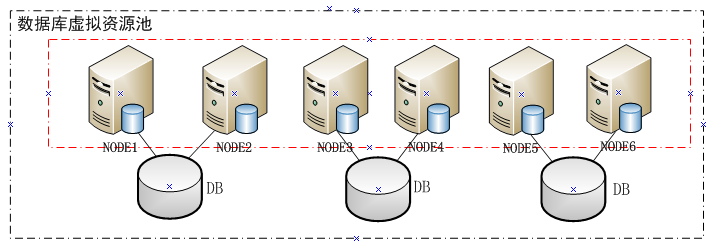
(图一)
图一中,内框里面6个节点沟通一个cluster。但这6个节点的cluster中,却人为的分成了三组,构成三组rac实例。其实这里面至少存在下面几个问题:
1.对负载较高的业务,可能会导致承载该业务的节点负载过高。实际上当时已经呈现,但负载在可控范围。
2.当承担业务的两个节点都出现故障中,即使有剩余节点,业务也没法自动漂移到剩余节点。虽然ip会漂移到其它节点,但因为其它节点并无相关实例,更无对应服务,所以依旧没法为down掉的节点上的业务提供服务。
我们预料到这种可能,并针对这种可能做了测试演练,并将演练的结果提交给了客户。
3.随着资源池业务的增加,集群节点会横向扩展时,业务的负载并不会自动扩展到新增加的节点。这点需要注意的时,可能有时客户确实不想业务自动扩展到新增的节点上,但即使这样,这种架构会让手工将业务扩展这些节点麻烦很多。实际上这个项目后期已经确定扩展到8个节点。
那么怎么解决上面的问题?如图二:
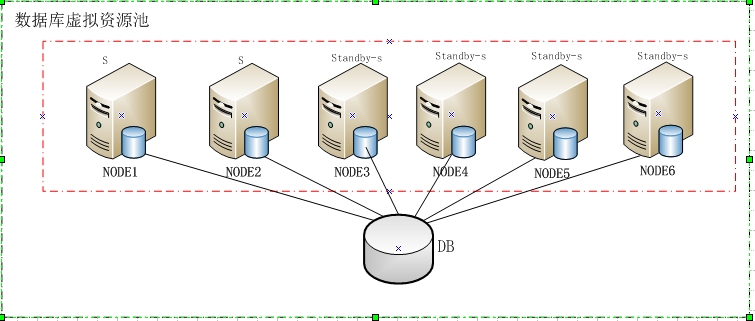
(图二)
我们当时给出的框架就是用好oracle的rac技术,就创建一组rac,包含六个节点。然后根据业务不同模块之间的耦合度创建服务。这种框架能很好的解决上面的问题,也可以最大程度上减少rac会带来的gc等待问题。
在创建服务时,会结合业务的耦合度和业务的负载来确定某一个业务需要几个节点来做为主节点,然后用剩下的节点做来备用节点。当然,每个节点都在做、作为某一个业务的主节点的同时,也同时作为其他业务的备用节点。理论上,只要有一个节点能提供服务,所有业务都能提供服务。
我接手这个项目时,这个所谓的资源池中已经接入了16套系统,创建了16套数据库。也许你猜对了,这个资源池,已经接入的系统,每套系统都对应一套库。
这里面的问题就在于一直以来的误区,觉得系统都应该有自己一个独立的库。其实这种架构有以下问题:
1.在一台服务器启动多个实例,由于分配了多个oracle后台进程和内存,必然会导致系统资源的浪费。
2.会造成不必要数据流动。不必要的数据流动很容易带来数据的不一致,以及数据的冗余等。
总之,应用系统和数据库实例(机器)没有直接的对应关系。一个实例可以为多个应用系统提供服务,而一个应用系统也可以在多个实例(机器)上运行,后者就是rac。
系统建设的一大趋势是数据集中。但数据集中不是简单的将分散的数据物理上搬到一起,也不是简单的系统数据堆积。而是应该从更高的角度真正实现也许系统数据的大整合、大集中、降低数据的冗余,保证数据的一致性,并尽量减少数据的流动性,提高数据的质量。在这种集中式的数据库中,各个系统以shema的方式集中存储在一个库中。可以根据每个业务的耦合情况以service的形式实现业务系统之间的负载均衡,故障回退,高性能等。
当时,我们也跟客户推荐了这种集中存储,客户主要担心两个问题:
1.系统出现问题,比如常见的性能问题,怎么明确责任?
2.面对一个很大的数据库,怎么备份和回复?
其实这两个问题,我们都给了客户很好的回答。我们说过,业务可以以服务的形式在某一个节点或者几个节点上运行,在不漂移的情况下,业务的负载是可以反馈到具体某一个或几个节点上,况且,某一个sql也能对应到某一个模块,性能定位不是问题。
关于第二问题,确实会让人感觉有些棘手。但实际上,分散存储的数据总量肯定会大于集中存储。所以在备份的总耗时上分散存储不会少于集中存储。对这种大型数据库,我们也不可能简单的做全库备份,oracle已经能很好的支持快速增量备份,这完全可以将备份时间控制在合适的时间窗口之中。
那么恢复呢?其实也很少会做全库恢复,我们可以做做块恢复,表空间恢复,数据文件恢复等。即使介质损坏,我们也只需要恢复存储在该介质上对应的数据就ok了,其他介质上数据对应的系统并不受影响。
当然,最终,数据库架构依旧是一个系统对应一个库。主要原因已经不是技术问题,而是在原有的系统中,这些系统的数据交互是专门由一家公司开发接口系统通过webserives技术来进行,一种慢且不安全的数据交互方式。但没办法,如果真的数据集中在一个库里面了,这个系统就要下线了。但这个系统因为种种原因,是绝对不能下线的,所以,最终这里的架构是这样的:在同一个rac中不同库之间,用一个第三方的接口系统保证数据流动。
也许只有让技术的归技术,政治的归政治,中国才能真正的强大起来吧。
资源池中数据库都是asm存储。这本身没有什么问题。真实的存储架构如下图:
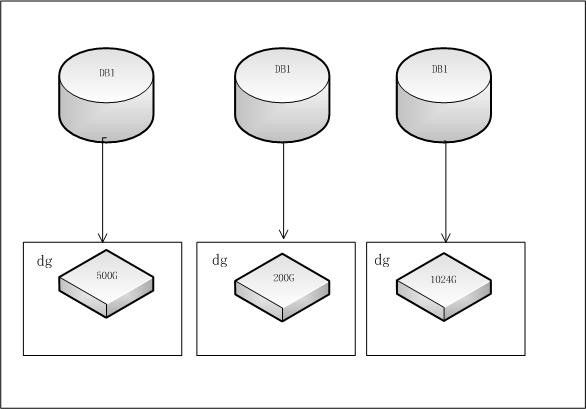
(图三)
你没有看错,是一个数据库对应一个diskgroup,而且一个diskgroup里面放一块磁盘。有一个库只有50G的数据,所以创建了一个对应的有200G磁盘的diskgroup。
我们没有机会与当时这么设计存储架构的工程师沟通当时这么设计的目的。但很明显,这么设计是因为对oracle的ASM技术不是很了解。
Oracle提供的ASM技术有很多优势,但这里我们至少需要了解一下几两个方面:
1.ASM技术里面包含的条带化和多种镜像功能。所以我们在使用ASM存储模式时,在创建diskgroup时,应该考虑使用尽可能大的盘,如果是LUN,则尽量分配大的LUN,并LUN分散到不同的物理磁盘中。
2.ASM技术可以让I/O操作均匀分散在多块磁盘中。所以我们在使用ASM技术来存储数据时,应该在同一个diskgroup中使用多块磁盘或者多个LUN。
但遗憾的是,上面这两点,在资源池的存储架构中,都没法体现出来。除此之外,这种存储架构,也会造成存储空间的极大浪费。
我个人觉得针对这种集中创建的数据库,存储架构也应该是集中式。如下图:
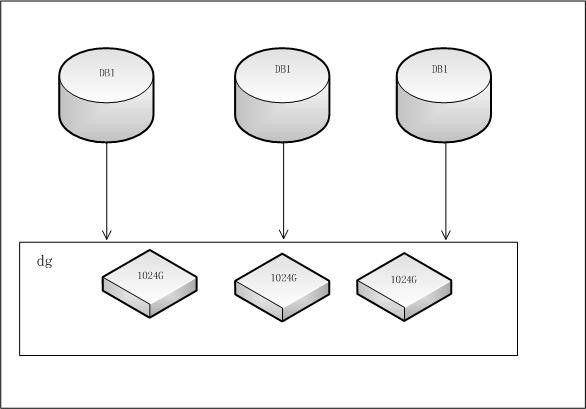
(图四)
后记:等我离开这个项目时候,我们已经将这种存储方案提交给客户。可能有人会觉得,为什么有些地方明知是错误却不去纠正?这也是我们纠结的问题。也许一个项目的成功,不仅仅取决于技术,还取决于这个团队是否做正确的事,而这个正确的事,有时在技术的角度来看,可能就是错的。
上一篇:IT黑盒运维浅析
下一篇:Elasticsearch与hadoop比较

新炬网络公众号